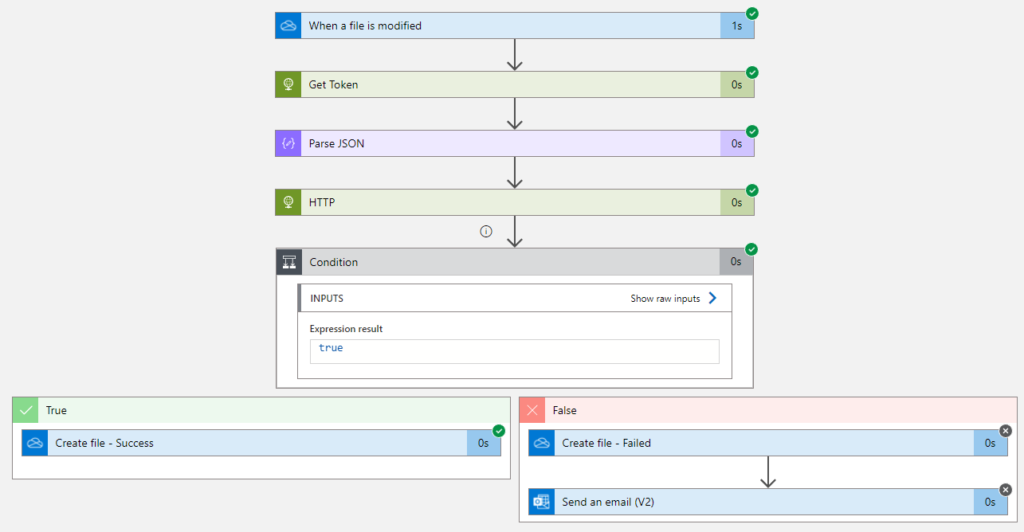
Architects as Lawmakers

In an enterprise context, architecture often resembles lawmaking.
Being an architect can feel like being a legislator. You are not building every system yourself — you are shaping the rules that determine how systems are built.
Good architecture, like good law, creates order without suffocating innovation.
Bad architecture, like bad law, creates friction, confusion, and endless debates.
Architecture Principles as a Constitution
Architecture principles are like a constitution.
They are:
- Stable
- High-level
- Value-driven
- Rarely changed
- Applicable across the entire organization
They define fundamental beliefs such as:
- Data is an asset
- Reuse before buy, buy before build
- Security by design
- Interoperability over isolation
A constitution does not specify speed limits or tax percentages.
It defines the foundations of the state.
Similarly, architecture principles do not define logging formats or API payload structures.
They define the values that guide all decisions.
If principles are unclear, inconsistent, or too numerous, everything built on top becomes unstable.
Architecture Policies as Laws
Policies are the laws derived from principles.
If a principle says:
Data is an enterprise asset.
A policy may state:
All business-critical data must have an assigned data owner and steward.
Policies are:
- Mandatory
- Enforceable
- More specific than principles
- Easier to change than principles
They operationalize the constitution.
For example:
Only technologies marked "Adopt" in the Tech Radar may be used in production.
All external APIs must be published via the enterprise API gateway.
All production systems must implement logging in accordance with the enterprise observability standard.
Workloads must be classified as operational or analytical and deployed to the corresponding platform.
All data flows between domains must be documented and approved before implementation.
All business-critical data must be governed in accordance with the enterprise data governance standard.
The difference between a policy and a standard is subtle but critical: a policy tells you what you must do. A standard tells you how to do it.
The Architecture Review Board as Government
An Architecture Review Board (ARB) functions like a government body.
It does not write every line of code.
It ensures compliance with the constitution and laws.
The ARB typically:
- Approves new policies
- Reviews exceptions
- Interprets principles in complex situations
- Updates governance when the environment changes
Its role is not to slow down progress. When governance works well, most decisions never reach the board - because policies already provide clarity.
Architecture Decision Records as Case Law
Architecture Decision Records (ADRs) are similar to case law.
They document:
- Why a decision was made
- What alternatives were considered
- How policies were interpreted
In a healthy organization:
- ADRs follow principles
- ADRs comply with policies
- Exceptions are explicit and justified
Over time, ADRs become institutional memory — much like legal precedents.
When Architecture Is Simple, Engineers Are Free
In a country where laws are simple, logical, and stable, it is easier to start a business and live well.
In an organization where architecture is well-defined:
- Engineers are autonomous
- Teams move faster
- Discussions are shorter
- Decisions are less political
Clear rules reduce friction.
Most work should not require special approval.
Only exceptions should need review:
- Introducing a new technology
- Deviating from a standard
- Expanding into previously uncovered territory
- Changing outdated policies
Good governance minimizes central intervention.
How to Enforce the Law?
The best law is the one people believe in.
If citizens understand that laws reflect shared values and create fairness, enforcement becomes mostly cultural rather than forceful.
The same applies to architecture.
Good architecture governance:
- Reflects real engineering needs
- Is not overly complex
- Is intuitive
- Is stable but adaptable
- Removes friction rather than adding it
When engineers believe the rules make their lives easier, compliance becomes natural.
If every rule feels arbitrary, enforcement requires "architecture police." I would prefer to do architecture work, not police work, and I bet you share this view, otherwise you would probably be reading some other blog right now ;)
The most effective form of enforcement is making the right thing the easy thing. This is where platform engineering comes in.
When a platform team provides golden paths - pre-configured templates, pipelines, and tools that already comply with policies - following the rules becomes the default, not the exception. Engineers do not need to read a governance document to get logging, authentication, or API standards right. They just use the platform, and compliance comes for free.
Good laws deserve good infrastructure. A policy without a golden path can easily become a wish. A policy backed by a platform is a reality.
Anarchy Is Expensive
Let's imagine a company in which every team was free to design APIs however they liked. Authentication methods differed. Error formats were invented on the fly. Versioning was a matter of taste. Access management was implemented in multiple ways. Observability as well. Teams did not even know who is using their APIs as access credentials were shared by consumers.
Wild west, no laws. Everyone had a gun but was not safe.
Now imagine a modernization or innovation initiative that aims to replace an old API that provides very valuable data assets. As that was a key API in the organization, the usage is all over the place. But nobody is sure who the consumers are. Which systems will be impacted by the migration?
Or another scenario - costs of handling API calls across the organization are growing. Company needs to review the costs and make sure that the external integrations actually bring value proportional to infrastructure consumption. How many requests fail? But there are tens of APIs and hundreds of consumers. No standard observability or access management. Answering the infra cost vs revenue from API usage becomes a very complex investigation, that needs to be done for each API separately.
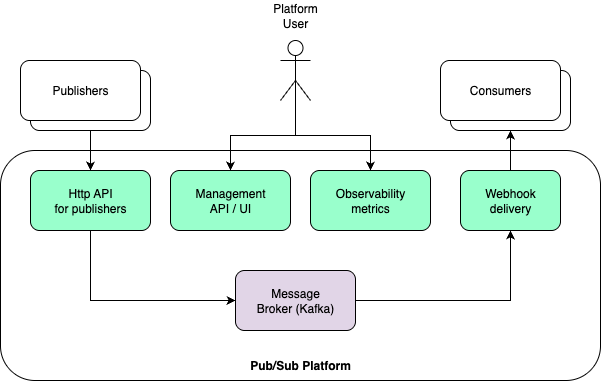
The situation would be very different if there were clear standards and policies for:
- Centralized API gateway usage
- Unique, traceable credentials per consumer
- Standardized authentication and authorization
- Mandatory structured logging
- Unified observability with shared metrics
- Explicit API ownership and documented consumers
Not hundreds of pages. Just a handful of laws that make the ecosystem predictable, and ideally platform-level capabilities that consistently implement those laws and make it easy to follow as part of the golden paths.
In a well-governed landscape, modernization is not archaeology. Cost analysis is not detective work. Innovation is not a risk to stability.
 image source:
image source: 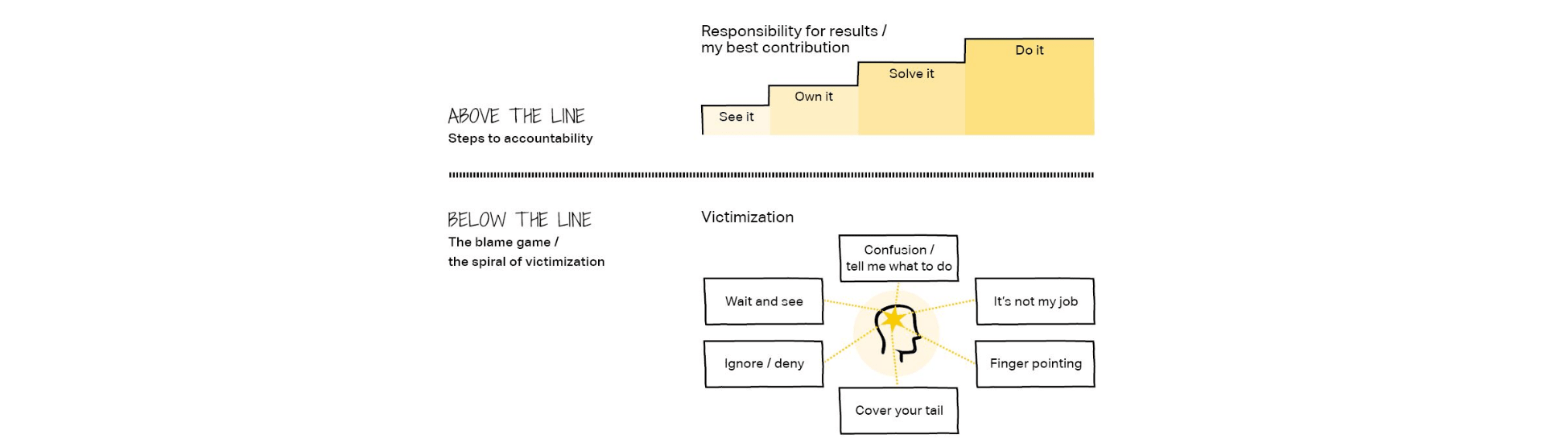 image source:
image source: