.NET MAUI vs Xamarin.Forms
I've been focusing recently on Xamarin and also following the updates on MAUI. MAUI was started as a fork of Xamarin.Forms and this is how it should be seen - as next version of Xamarin.Forms. There will be no version 6 of Forms (current is version 5). Instead, Xamarin.Forms apps will have to be upgraded to MAUI - Multi-platform App UI. Alternative to upgrading is staying on Xamarin.Forms 5, that will be supported only for 12 months after MAUI official release. So if we want to be on supported tech stack, then we need to start getting familiar with MAUI.
MAUI and also whole Xamarin framework will be part of .NET 6. It was initially planned to release MAUI already on November 2021 with the new .NET release. Now we know that production-quality release was postponed to Q2 2022. Instead of production-ready release, we will keep getting preview versions of MAUI. It also means that Xamarin.Forms will be supported longer (Q2 2022 + 12 months).

OK, but what changes we can expect with MAUI? Below the summary of key differences when compared to Xamarin Forms 5.
1. Single project experience
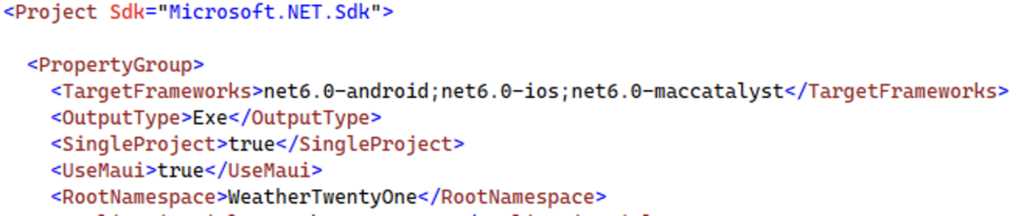
In Xamarin.Forms we need to have separate project(s) for each platform and also project(s) for shared code. In MAUI we have an option to work with single project only that can target multiple platforms:
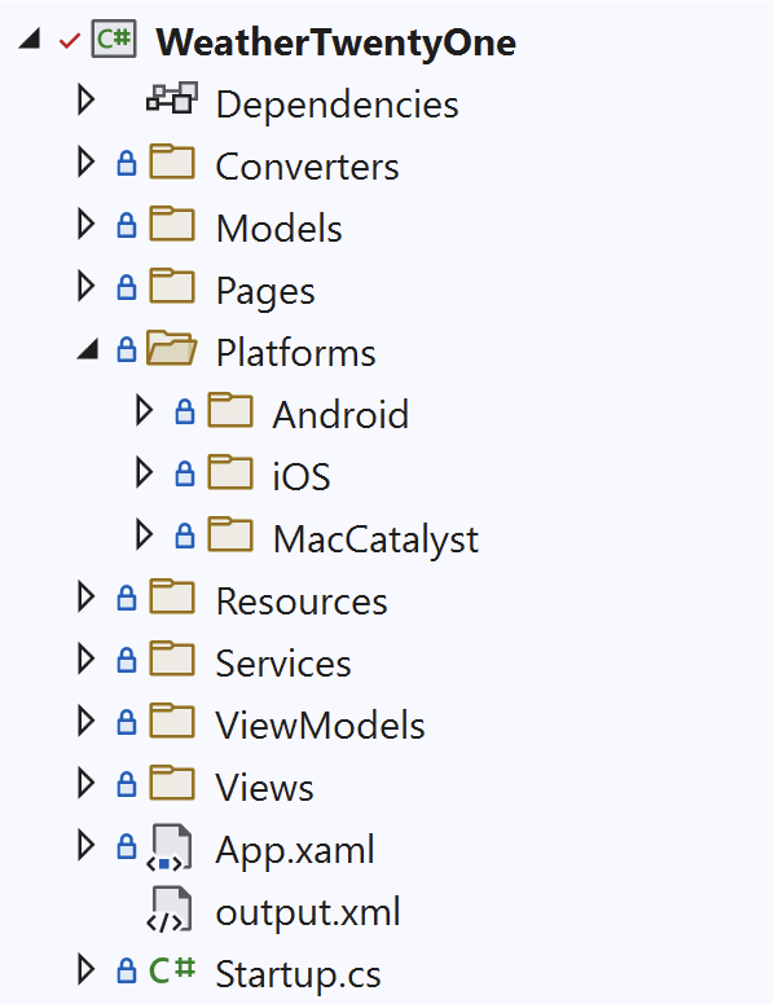
In single project we can still have platform-specific directories (under "Platforms" directory) or even have platform specific code in single file by using pre-process directives:
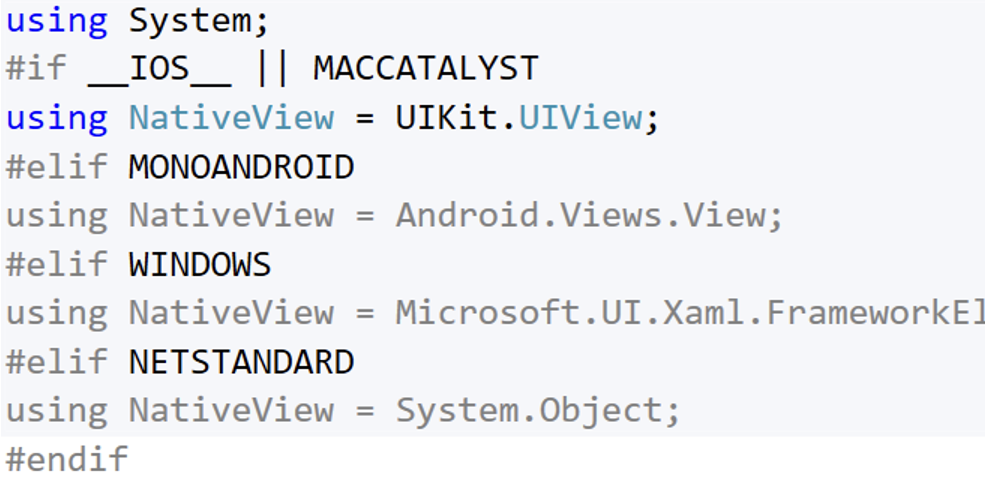
This is not something that MAUI introduced, this is achieved thanks to so SDK-style projects which are available in .NET 5. Already in .NET 5 we can multi-target projects and instruct MS Build which files or directories should be target-specific.
Example of multiple target in SDK-style project in csproj:
Example of conditional compilation based on target:

So this is not a MAUI magic, it is just about using .NET 5 capabilities.
2. Central assets management
Consequence of consistent single-project experience is also the need to manage assets in a single project. MAUI accomplishes that for PNG and SVG images by doing compilation-time image resizing. We can still have platform-specific resources if needed, for example for other formats.
But again, it is not a revolutionary change. MAUI is just integrating ResizetizerNT as integrated part of the framework.
So this MAUI feature is another low-hanging fruit. It was possible to achieve that also with Forms, but now you do not have to add additional libraries.
3. New decoupled architecture
New architecture seems to be the change where most of the efforts of MAUI team goes. This change is actually significant. It is a big refactoring of Forms driven by new architecture called Slim Renderers.
Slim renderers was kind of temporary name, so let's not get used to that. The term that we should remember and get familiar with is Handler. Role of Renderers from Xamarin.Forms is taken by Handlers in MAUI.
What's the main difference? We can summarise it with one world: decoupling. This is how it looks in Xamarin.Forms:
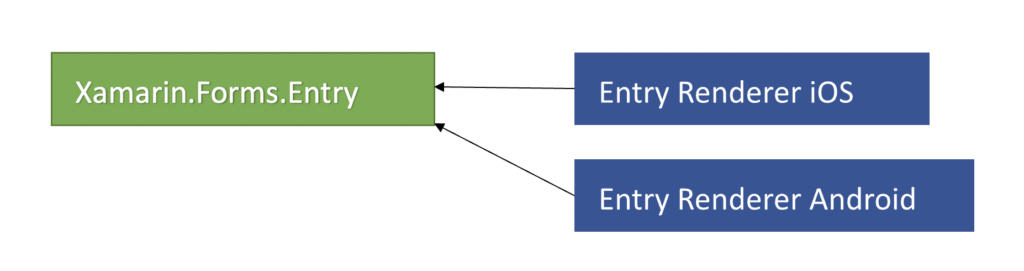
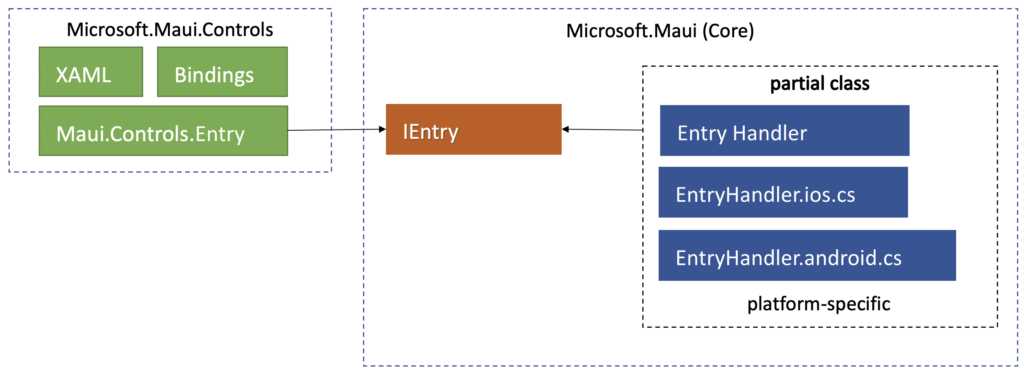
Renderers, that produce native views tree depend on Forms controls. In the above diagram you can see example for Entry control on iOS and Android platform but the same idea applies for other controls (like Button, Label, Grid etc) and other platforms (Windows, MacOS).
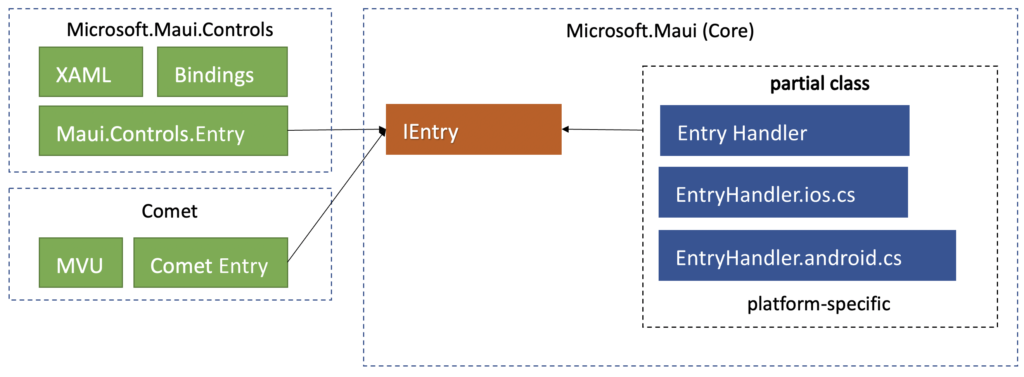
MAUI introduces new abstraction layer of controls interfaces. Handlers depend only on interfaces, but not on the implementation of UI controls:
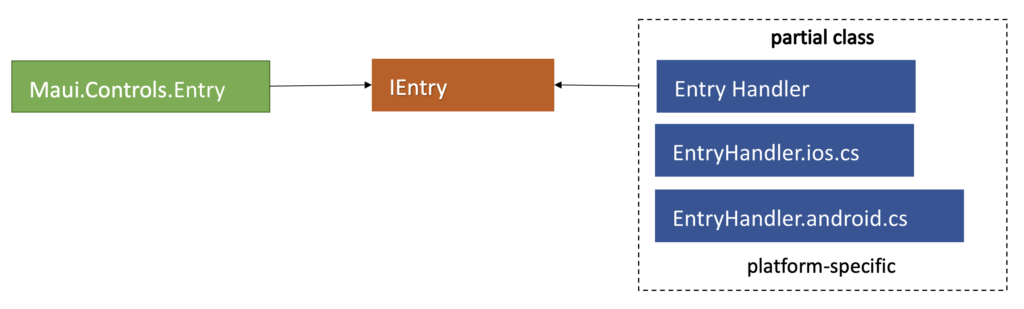
This approach allow to decouple the responsibility of rendering platform-specific code that is handled by handlers from the implementation of the UI framework. MAUI is split into Microsoft.Maui.Core namespace and Microsoft.Maui.Controls namespace:
What is important to notice, is that support for XAML or bindings implementation was also decoupled from handling platform specific code. It makes the architecture much more open for crating alternative UI frameworks based on Maui.Core, but using different paradigms. We can already see experimental framework Comet using that approach and proposing MVU pattern instead of MVVM:
There is also a rumour around MAUI project that Fabulous framework could follow that path, but an interesting thing is that Fabulous team does not seem to share the enthusiasm ;) It will be interesting to see how the idea of supporting F# in MAUI will evolve.
But it is important to notice that MAUI does not have built-in MVU support. MAUI Controls are designed to support MVVM pattern that we know from Xamarin.Forms. What is changing, is the open architecture enabling alternative approaches, but alternatives are not built-in into MAUI.
4. Mappers
Ok, so there is no Renderers, there are Handlers. So how to introduce custom rendering when needed? Since there is no custom renderers, can we still have custom rendering? Yes, but we need to get familiar with one more new term in MAUI: Mappers.
Mapper is a public static dictionary-like data type exposed by Handlers:
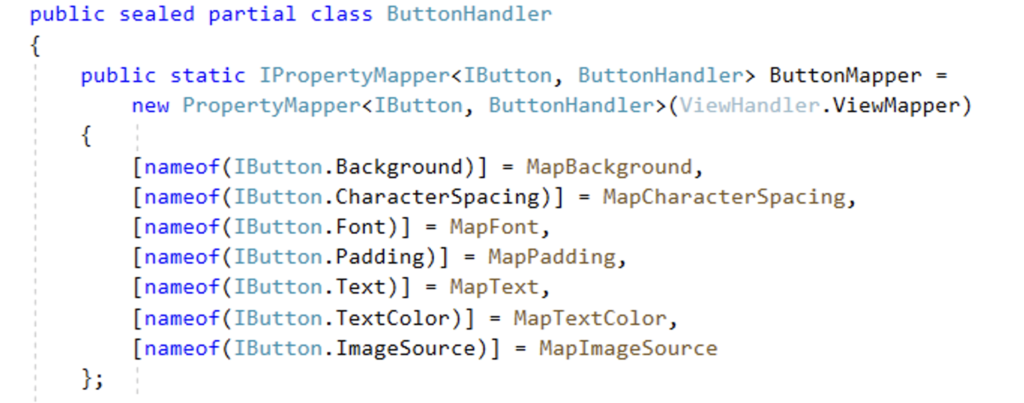
It maps each of the properties defined on controls interface into a platform-specific handler function to render given property.
If we need custom behaviour we can just map our own function from our application:
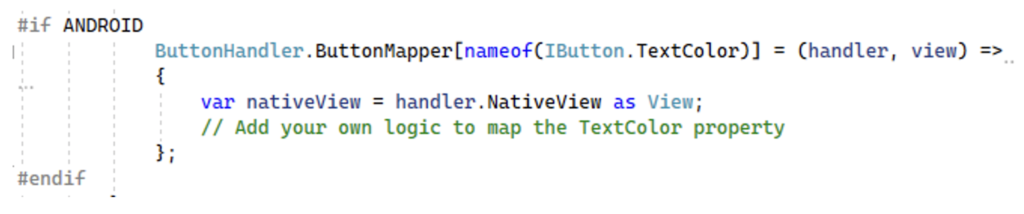
See this repository created by Javier Suárez with examples and detailed explanations on how to migrate from Forms to MAUI: https://github.com/jsuarezruiz/xamarin-forms-to-net-maui
And do not worry about your existing custom renderers, they will still work thanks to MAUI compatibility package. Although it is recommended to migrate them into handlers, to get the benefits of improved performance.
5. Performance improvements
The goal of new architecture is not only to decouple layers, but also to improve performance. Handlers are more lightweight compared to renderers, as each property is handled in a separate handler instead of having one big rendering function to update the whole component.
MAUI also avoids assembly scanning at startup to find custom renderers. Custom handlers for your custom controls are registered in an explicit way on app Startup:

One more performance improvement should be reduced view nesting. Forms have the concept of fast renderers, in MAUI all handlers should be by design "fast".
But MAUI release was not postponed without any reasons. The team is still working on performance improvements. First benchmarks are showing that MAUI apps start even slower than Forms apps, see this issue for details: https://github.com/dotnet/maui/issues/822. In this case observed difference is not dramatic, it is 100ms, but still, we should not take for granted that MAUI is already faster.
6. BlazorWebView
Do you like to use Blazor for web UIs? Great news, with MAUI you will be able to use Blazor components also on all the platforms supported by MAUI (Android, iOS, Windows, MacOS). Components will render locally into HTML. HTML UI will run in web view, but it will avoid web assembly or SingalR, so we can expect relatively good performance.
And what is most important, Blazor components will be able to access native APIs from code behind! In think this is a great feature that opens scenarios for interesting hybrid architecture (combining native and web stack in a single app).
See this video for details: Introduction to .NET MAUI Blazor | The Xamarin Show
7. C# Hot Reload
And last but not least, since MAUI will be part of .NET 6 it will get also all other benefits that are coming with .NET 6. And one of them is hot reload for C# code. In Forms we have hot reload only for XAML, so it is a great productivity improvement, especially for UI development.
Summary
MAUI introduces significant changes but this framework can be still considered as evolution of Forms. Fingers crossed that it will reach Forms 5 stability and will make the framework even better thanks to the above improvements.